

- Rich, structured rendering of message lists
- Token and cost tracking per LLM call, per trace and across traces over time
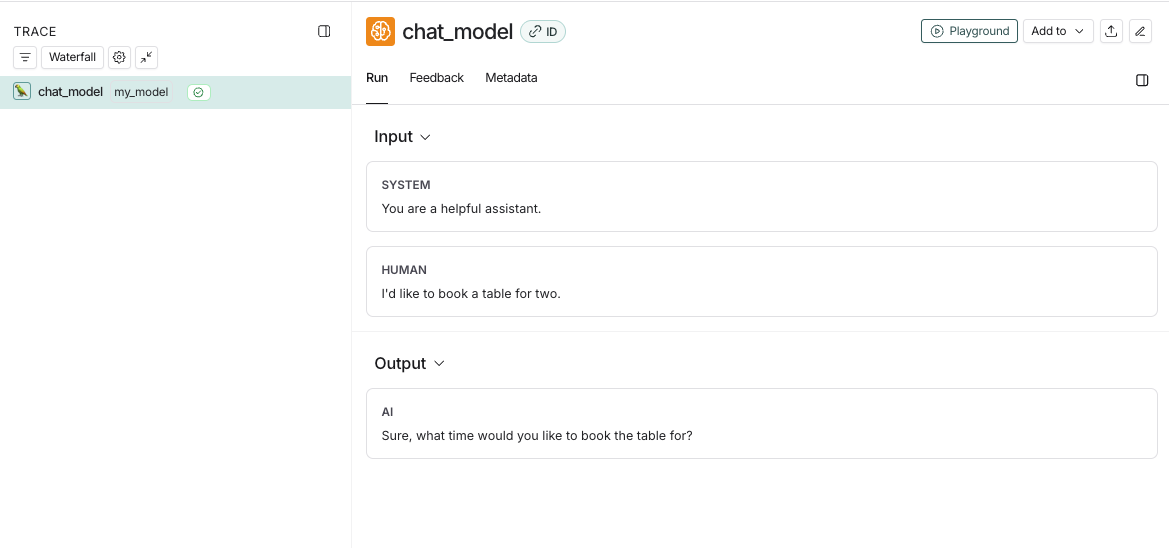
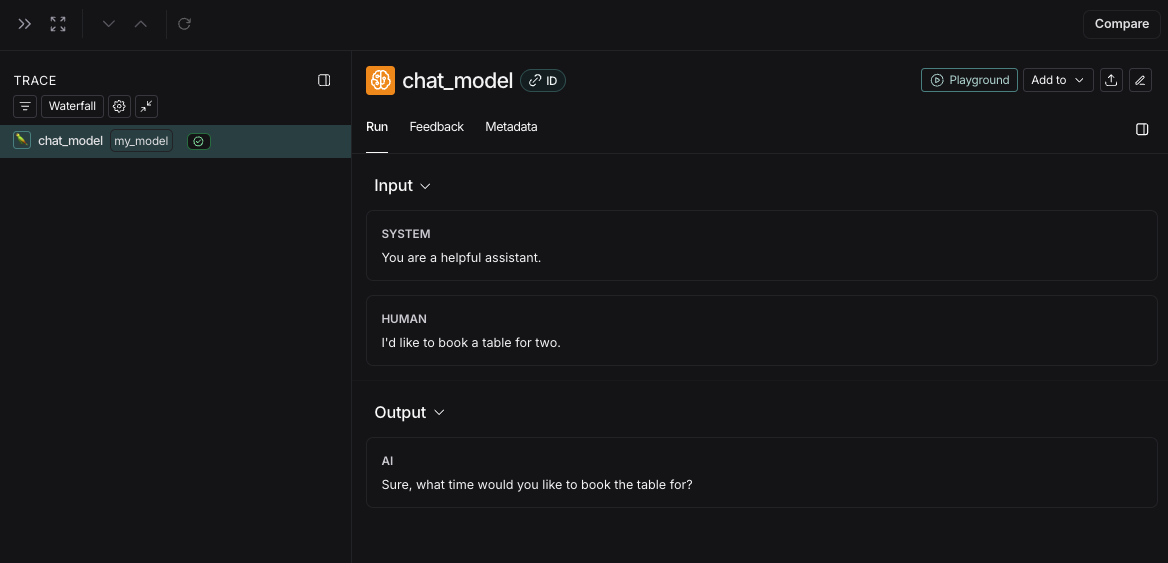
Messages Format
When tracing a custom model or a custom input/output format, it must either follow the LangChain format, OpenAI completions format or Anthropic messages format. For more details, refer to the OpenAI Chat Completions or Anthropic Messages documentation. The LangChain format is:Examples
Converting custom I/O formats into LangSmith compatible formats
If you’re using a custom input or output format, you can convert it to a LangSmith compatible format usingprocess_inputs/processInputs and process_outputs/processOutputs functions on the @traceable decorator (Python) or traceable function (TS).
process_inputs/processInputs and process_outputs/processOutputs accept functions that allow you to transform the inputs and outputs of a specific trace before they are logged to LangSmith. They have access to the trace’s inputs and outputs, and can return a new dictionary with the processed data.
Here’s a boilerplate example of how to use process_inputs and process_outputs to convert a custom I/O format into a LangSmith compatible format:
Identifying a custom model in traces
When using a custom model, it is recommended to also provide the followingmetadata fields to identify the model when viewing traces and when filtering.
ls_provider: The provider of the model, eg “openai”, “anthropic”, etc.ls_model_name: The name of the model, eg “gpt-4o-mini”, “claude-3-opus-20240229”, etc.
If
ls_model_name is not present in extra.metadata, other fields might be used from the extra.metadata for estimating token counts. The following fields are used in the order of precedence:metadata.ls_model_nameinputs.modelinputs.model_name
metadata fields, refer to the Add metadata and tags guide.
Provide token and cost information
LangSmith calculates costs derived from token counts and model prices automatically. Learn about how to provide tokens and/or costs in a run and viewing costs in the LangSmith UI.Time-to-first-token
If you are usingtraceable or one of our SDK wrappers, LangSmith will automatically populate time-to-first-token for streaming LLM runs.
However, if you are using the RunTree API directly, you will need to add a new_token event to the run tree in order to properly populate time-to-first-token.
Here’s an example: